
Does gRPC address the warnings of these computer scientists?


How lovely would it be if writing a function that interacts with a distributed system is as easy as writing one executes locally?
That is part of the goals or vision of technology such as RPC. One just needs to whip up a definition file and client code would be autogenerated. Everything else is handled within the library and the user would just need to tweak a few things here and there to tune it just the way s/he needs it. Sounds great and at a glance seems very achievable. But, the writers of the paper titled A note on distributed computing thinks that there are pitfalls to this idea.
The paper came out in 1994. Surely things have progressed a lot since then. So, how does gRPC fares against the concerns raised in the paper?
Spoiler: It’s mostly good.
Terminologies
Let’s start by clarifying the two main terms used in the paper, local and distributed.
Local computing would be any computation that runs within the same address space, which is the memory allocated by the OS to the process running the program. Distributed computing, on the other hand, would be running in different address space, meaning they don’t share the same memory and can even run on different machines.
Next would be RPC. The paper's main focus was on distributed objects and not RPC. The paper only mentions RPC to draw similarities with distributed objects because RPC was to distributed functions as CORBA is to distributed objects. Due to the similarities, whatever discussed for distributed object would also apply to RPC.
The Vision and The Problem
One of the core ideas of tech like RPC, is to have a unified style of programming. A function could be calling a machine in a different continent and another just doing CPU bound computation. And just looking at both functions call, one might not spot a difference.
If you have ever written logic for making a remote request, you’ll understand the amount of boilerplate and consideration that has to go into it.
In reality though, both local and distributed calls have different properties and needs to be handled differently. With a unified model, it would be easy for a programmer to treat both type of function similarly, which would be unwise.
Consider the two following functions:
int resultA = await moduleA.incrementValue();
int resultB = await moduleB.incrementValue();Both looks the same with the same type signature. At a glance, it is difficult to tell which one actually makes a remote call and which runs locally. It may seem like a small thing but can lead to mistakes and errors.
Let’s do a thought experiment. Imagine that you have been requested to transport two unmarked boxes. Both boxes look similar and have almost similar weights. You know nothing much about the content. How would you carry these boxes into your vehicle and move them to their destination? Would you act differently if you were told that one of the boxes contains very fragile contents?
The boxes being similar represents the unified model and the different treatments demanded by different contents represents the challenge of RPC and other similar ideas.
Let’s see if any of those problems are still relevant with gRPC.
Partial Failure and Concurrency
We shall start with the most complex one (the paper discussed this last).
Consider an gRPC client making 3 separate requests, like below:
var resultOne = await rpc.CallOne();
var resultTwo = await rpc.CallTwo();
var resultThree = await rpc.CallThree();Partial failure is what happens when the 3rd and last call fails. For a local execution, especially if it is not doing any IO like writing to disk, throwing an exception or returning an error might be good enough to restore the state. And retrying again will be as though the failure never happened.
But, this is not the case for the RPC requests above. The states for the first two requests are already committed in the RPC server and simply throwing an exception is not enough to restore the state. Some error correcting requests need to be performed to restore it. If it could be corrected.
What’s worst is when an RPC client only makes a single request to the server which splits into multiple requests to downstream. If one of the dependency requests fails, the RPC client would have a tough time recovering, as a simple retry would not resolve the problem.
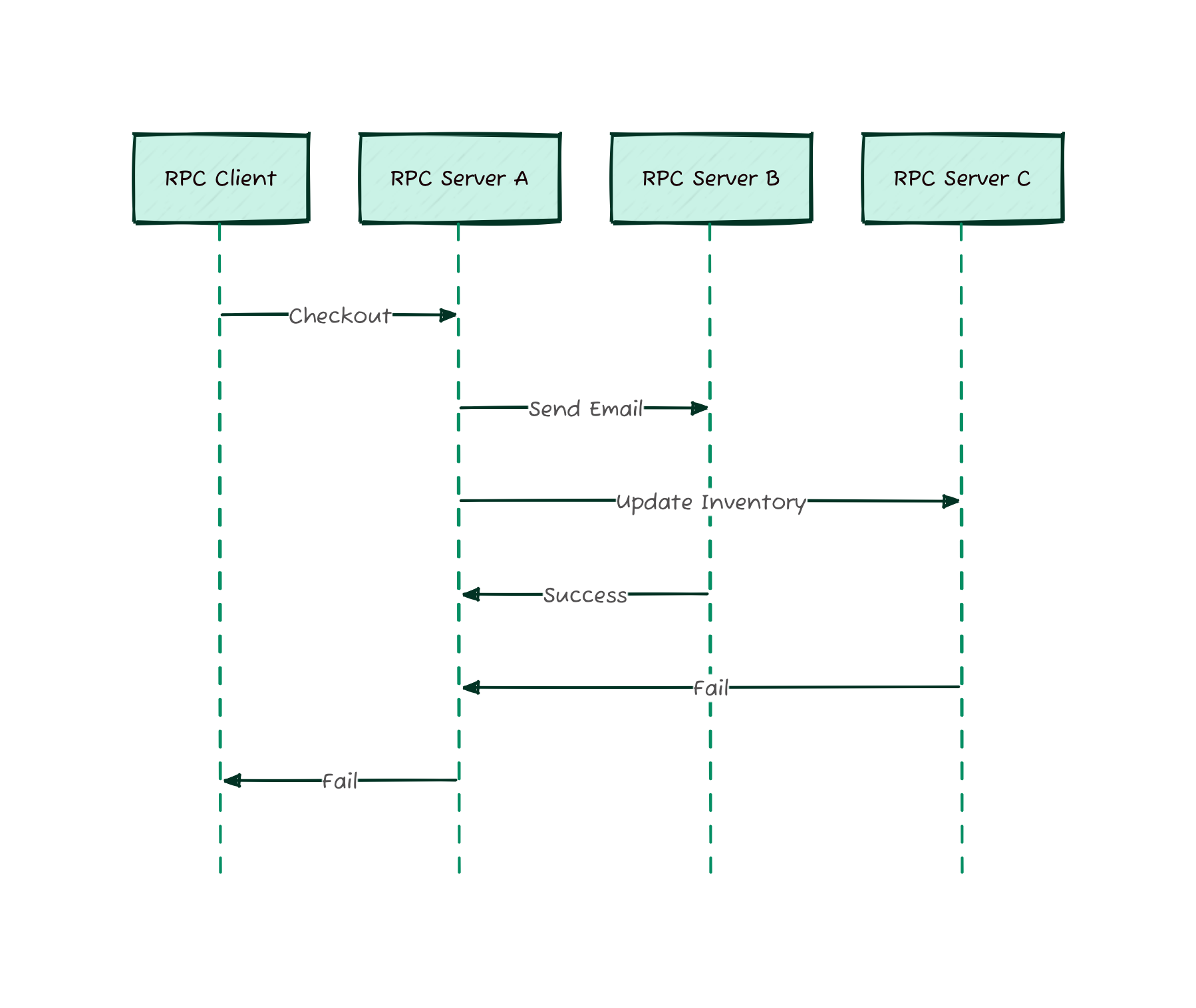
This is the main point that the paper would like to drive. The dream of having a unified model for both local and distributed objects/functions is hard to impossible to achieve due to the nature of distributed system.
When a distributed system fails, it needs to inform whether the error was due to network or logic. Moreover, it needs a way to inform if the error is recoverable or the state restorable. Finally, from this information, the client would then need to execute the error recovery steps.
Other than failures, there are also the challenges that come together with concurrency. One of the common difficulties is out of order operations. Because steps are not executed in sequence, but running concurrently, it must be expected that operations can be completed out of order. Therefore, precautions must be added into the code to handle the issue.
Writing all those breaks the illusion that there is no difference between local and distributed computing. gRPC still shares the same issue.
Memory Access
The example the authors gave for this was using pointers for the function’s arguments.
Because distributed systems runs in separate address spaces, certain pointer related operations cannot be used, e.g. passing the memory address. Preventing such memory related operations for distributed functions breaks the unified model illusion.
In my humble opinion, it is not really a dealbreaker, especially for high-level languages such as C# where memory related operations are rarely done, especially with pointers. It is more idiomatic to pass objects and other datcastrutures as arguments and let the GC manage everything else.
On top of that, at least for gRPC, the .proto definition file has no way to describe pointers for parameters. Therefore, invalid pointer operation such as passing the address is not doable. And for operation such as passing value at the address, e.g *pointerVar, it should just work.
A non-issue for gRPC when using with high-level language such as C#. If used with lower level languages, such as C++ or to a certain extent, Golang, where pointer related operations are more common, then the restrictions and difference between local and remote calls would be more glaring.
Latency
According to the paper, this is the least problematic concern. And I have to agree.
The basic premise is that, remote calls can take a lot longer than local calls. You might argue that local calls can take a long time to complete as well, e.g. polynomial time algorithms or doing heavy disk bound operations. But, more often than not, remote calls requires much more time to complete than local calls. And if remote calls look and feel the same as local calls, it might cause performance issues for the program when not organized properly in the code base.
I would say, this is where modern development and language choice matters the most. Back when the paper was published (1994), async-await model for programming languages was not a thing yet. That only appeared in 2007 in F# and a few years later dropped in C#. Erlang already existed since the late 80s with message passing, which is also non-blocking model. But it was a proprietary language until 1998 when it was finally open sourced. To be fair, the authors did highlight about this in the paper.

This point is only a concern if gRPC is used in languages that do not have non-blocking model. It should not be an issue with gRPC for languages like C#, F# or Golang.